Some Histories and Futures
of Making Music with Computers
Roger B. Dannenberg Carnegie Mellon University
rbd [at] cs.cmu.edu
http://www.cs.cmu.edu/~rbd/
Korean-translated by Youngmi Cho; assisted by Joong Hoon Kang
Abstract
Having spent decades working in the field of Computer Music, I review some major trends of artistic and scientific development in the field with an eye to the future. While the implications of exponential computational growth are hard to predict, it seems that musical imperatives remain stable; thus, they will continue to guide us in the future. I predict a number of “futures” for Computer Music based on the persistent themes of sound creation, music representation, and music performance.
Keywords
History of computer music, Futures of making music with computers, Moonshot project.
컴퓨터로 음악만들기의 어떤 역사와 미래
로저 비 다넨베르그카네기멜론 대학교
rbd [at] cs.cmu.edu
http://www.cs.cmu.edu/~rbd/
조영미 번역; 강중훈 교정 및 번역보조
초록
수십년간 컴퓨터음악 분야에 종사하면서 내가 겪었던 몇몇 주요한 예술적, 과학적 발전 경향을 이 분야의 미래에 대한 관점과 함께 되짚어본다. 기하급수적인 컴퓨터 성장의 영향정도를 가늠하기란 어렵겠지만, 음악에 대한 요구조건에는 변함이 없어 보인다; 그러므로, 우리는 이 요구조건들을 통해 미래의 길을 따라가 볼 수 있을 것이다. 나는 사운드 창작, 음악적 표현, 그리고 연주 실행이라는 지속적인 주제를 바탕으로 한 컴퓨터음악의 몇몇 “미래들”을 예측해본다.
주제어
컴퓨터음악의 역사, 컴퓨터로 음악만들기의 미래, 문쇼트 프로젝트.
Introduction
Like computing itself, Computer Music has experienced rapid growth over sixty years or so. We have seen an evolution starting from primitive but pioneering attempts to create the first digital musical sounds and to create and control music algorithmically. Our current state of the art now includes very sophisticated real‐time signal processing, flexible software languages and architectures, and commercialization that reaches billions of creators and consumers. I am honored to address the KEAMS Annual Conference 2020, and I would like to take this opportunity to look both backward and forward with an aim to better understand the field and perhaps to gain some insights into future artistic opportunities and scientific directions.
Most of my work in the field has been scientific, but I feel that my work has always been guided by my experience as a performing musician and composer. My early interests in math, music and engineering led me to analog music synthesizers as well as computers in my teens. (I should add that computers around 1970 were rarely encountered outside of businesses and universities.) Through college, I learned enough electrical engineering to design and build a hybrid digital and analog synthesizer as well as a microcomputer of my own design and wired by hand, but I was pretty ignorant of emerging research. At least I was well prepared to suddenly discover a small but growing literature from authors and editors such as Max Mathews, Jim Beauchamp, John Chowning and John Strawn. I spent my years in graduate schools in more mainstream Computer Science, but on the side, I devoured everything I could find to read on Computer Music. I emerged from graduate school with a junior faculty position and a very supportive, open‐minded senior faculty including Nico Habermann, Raj Reddy, Alan Newell, Herb Simon, and Dana Scott. Ever since then, I have been very fortunate to follow my passion for Computer Music making and research. I have closely followed and participated in over four decades of Computer Music development.
In this presentation, I wish to review some of my own work, which like all research is tangled in a network of other ideas and influences. From this, I hope to draw some understanding of the big ideas that drive the field forward. The occasion of a keynote address is one of those rare opportunities where one can be controversial and speculative. I will take this chance to make some
predictions of where we might be going in the future. I have titled this talk in the plural: both “histories” and “futures” to hedge my bets. There are multiple ways to organize the past and multiple possibilities for the future. And speaking of the title, the phrase “with Computers” is purposefully ambiguous, regarding computers as both tools and collaborators. I will surely omit some important
history and fail to anticipate much of what is yet to come, but I hope these ideas might inspire some or at least offer interesting insights.
서론
컴퓨터의 사용 자체가 그러했듯, 컴퓨터음악은 지난 60여 년 간 급속한 성장을 경험했다. 우리는 원시적이었지만 선구적이었던 첫 디지털 음악 사운드를 만드는 시도부터, 알고리즘으로 음악을 창작하고 제어하는 데까지 진화를 목격했다. 지금 예술의 현 수준은 매우 정교한 실시간 신호처리와 유연한 소프트웨어 언어와 구조체계architectures, 그리고 수십억의 창작자와 소비자를 포괄하는 상업화에까지 이른다. 나는 2020년 한국전자음악협회 연례학술대회에서 연설하는 것을 영광으로 여기며, 과거와 미래를 살펴봄으로써 이 분야를 보다 잘 이해하고, 미래의 예술적 가능성과 과학적 방향성에 대한 통찰을 얻는 기회를 갖고자 한다.
나는 이 분야에서 대부분 과학적인 작업들을 해왔지만, 연주하는 음악가이자 작곡가로서의 경험이 언제나 그 작업들을 이끌었다고 느낀다. 내가 10대 때 수학과 음악, 공학에 대한 초기의 관심이 아날로그 뮤직 신서사이저와 컴퓨터로 이어졌다. (1970년경 컴퓨터는 기업이나 대학 외에서는 접하기 어려웠다는 점을 덧붙인다.) 대학시절, 나는 디지털과 아날로그 혼합의hybrid 신서사이저 뿐 아니라 내가 직접 디자인하고 배선한 개인 컴퓨터를 설계하여 만들만큼 충분한 전자공학을 익혔으나, 새롭게 떠오르는 연구 분야에는 꽤 무지했다. 최소한 나는 맥스 매튜스Max Mathews, 짐 보샹Jim Beauchamp, 존 차우닝John Chowning, 존 스트론John Strawn과 같은 저자 겸 편집자의 작지만 점차 성장하고 있는 문헌들을 불현듯 발견할 만큼은 준비되어 있었다. 대학원에서 수 년간은 보다 주류의 컴퓨터 공학을 공부했지만, 한편으로는 내가 찾을 수 있는 한 모든 컴퓨터음악에 대한 읽을거리를 찾아 탐독했다. 내가 대학원에서 초급 교수직을 맡았을 때, 니코 하버만Nico Habermann, 라 레디Raj Reddy, 앨런 뉴얼Alan Newell, 허브 사이먼Herb Simon, 다나 스콧Dana Scott을 포함한 매우 협조적이며 열린 사고를 가진 상급 교수진을 만나게 되었다. 그 이후로 죽, 컴퓨터음악을 제작하고 연구하는데 나의 열정을 쫓아 가는 행운을 얻게 되었다. 나는 40년 이상 컴퓨터음악 발전 과정에 깊숙이 관여하며 함께해왔다.
이 발표에서, 모든 연구가 그러하듯 여러 다른 아이디어와 영향력이 네트워크로 얽혀 있는 몇몇 나의 작품들을 살펴보고자 한다. 이를 통해, 컴퓨터음악이 진일보할 원대한 생각에 관한 이해를 이끌어낼 수 있기를 바란다. 기조연설의 경우는 논쟁적이거나 추론적으로 사고해볼 수 있는 드문 기회일 것이다. 나는 이 기회를 빌려 우리가 미래 어디쯤 가있게 될 것인지 몇 가지 예측을 할 것이다. 이러한 나의 불확실한 예측의 위험성을 보완하고자 나는 이 연설 제목에서 “역사들”과 “미래들” 양쪽에 복수형을 사용했다. 과거를 정리하는 데 여러 방식과, 미래에 대한 다양한 가능성이 존재하기 때문이다. 그리고 제목에 대해 말하자면, “컴퓨터로”라는 문구는, 컴퓨터를 도구로서와 창작에 협력 주체로서 간주하므로, 다의적 의미를 의도한다. 나는 분명 몇몇 중요한 역사를 빠뜨리고 향후 오게 될 것들 중 많은 점들을 놓치게 되겠지만, 이러한 나의 논의가 누군가에게 영감을 주거나 적어도 흥미로운 식견이 될 수 있기를 희망한다.
Why Computer Music?
Anything new, any break with tradition, is going to raise questions. For some, computers and music seem a natural combination – why not? For others, as if the pursuit of Computer Music detracts from something else, what is the point? I have been collecting answers for many years, although I think there are really just a few. One idea that I was introduced to by F. Richard Moore is the precision that digital computation brings to music. Instead of music where every performance is unique, computers give us the possibility of precise reproduction, and thus incremental refinement of sounds with unprecedented levels of control.
Another important idea is that composers, rather than create directly, can create through computational models of composition. This has two implications. The first is that computational processes can be free of bias, so just as a tone row might help to liberate a composer from tonal habits, a computer model might create new musical structures and logic that the composer could not create directly. The second implication is that composers can inject new musical logics or languages into real‐time interactive performances. This enables a new kind of improvised music where performers are empowered to bring their expressive ideas to the performance, but
computers can enforce the compositional plans and intentions of the composer. It is as if the computer program becomes a new kind of music notation, constraining the performer in some respects, but leaving expressive opportunity in others. In my view, this is a powerful extension of aleatoric writing, which prior to computing found only limited ways to split musical decisions between the performer and composer.
These rather technical rationale for Computer Music, important as they may be to justify our work, are really just excuses for us to do what we love to do. Humans have an innate fascination with technology and automation. As soon as you tell someone that a robot is involved, the story is immediately interesting. Experiments by my advisee Gus Xia, et al. (2016) give evidence to what I call the “robot effect:” Suppose a human performs along with an audio recording, as in mixed music performances. How can we make the performance more engaging for the audience? One approach is using interactive, responsive, automated computer accompaniment. This in fact does not help much. Another approach is humanoid robot performers playing a fixed score, as in animatronics, but this does not help much either. However, if we combine computer accompaniment with humanoid robots to create interactive robot performers, then the audience finds the performance more engaging and more musical! This is evidence that we are innately attracted to the automation of human tasks, and what could be more human than making music?
All of the ideas above combine with a basic urge to explore and learn. Do we really need an excuse or rationale? Let us pursue our passion and see where that leads. After so many contributions to the arts, science, and culture, we no longer have to worry whether we are on a good path. Let us now try to characterize the path we are on and where it might lead.
왜 컴퓨터 음악인가?
새로운 것, 전통과 단절된 어떠한 것은 의문을 가지게 한다. 누군가에게 컴퓨터와 음악은 자연스러운 결합으로 보인다 – 왜 안되겠는가? 다른 누군가에게는 마치 컴퓨터 음악을 만드는 것이 다른 어떤 것을 훼손하는 것처럼, 요점이 무엇인가 묻는다. 내가 생각하기에 실제로는 몇 개 되지 않겠지만, 나는 여러 해 동안 해답을 찾아 모아왔다. 첫 의견은 리차드 무어Richard Moore가 알려준 것으로, 디지털 계산 처리가 음악에 부여하는 ‘정확성precision’이다. 모든 음악이 각기 다르게 연주되는 것과 달리, 컴퓨터는 정확한 재생산과, 그에 따라 전례없이 높은 수준의 제어력으로 소리의 추가적인 개선이 가능하다.
또다른 중요한 의견은, 작곡가가 직접 창작하지 않고 컴퓨터 전산처리를 통한 작곡 모델을 사용하여 창작할 수 있다는 것이다. 이에는 두 가지 방식이 있다. 첫째로 전산 처리는
편향에서 자유로울 수 있기 때문에, 한 음렬이 작곡가의 조성적 습관에서 벗어나도록 돕는 것처럼 컴퓨터 모델이 작곡가가 스스로 할 수 없는 새로운 음악적 구조와 논리를 만들어 주는 것이다. 두 번째 방식은 작곡가가 실시간 인터랙티브 공연에서 새로운 음악적 논리와 언어를 실시간으로 적용하는 것이다. 이것은 공연 시 연주자의 생각대로 연주할 수 있는 권한이 주어지는 즉흥 음악의 새로운 종류를 가능케하는데, 컴퓨터가 작곡가의 작곡 계획과 의도대로 즉흥 연주를 실행할 수 있게 된다. 이는 마치 컴퓨터 프로그램이 하나의 새로운 악보가 되어서, 어떤 면에서는 연주자를 제한하기도 하지만, 다른 면으로는 표현할 여지를 남겨두는 것 과도 같다. 나의 관점으로 보면, 이것은 컴퓨터를 사용하기 이전에는 그저 연주자와 작곡자가 음악적 결정을 제한된 방식으로만 나눌 수 있었던 우연성 작곡기법aleatoric writing이 강력하게 확장된 것이다.
이러한 컴퓨터 음악의 기술적 근거가 우리의 작업을 정당화하는데 중요할 수 있겠지만, 사실 이는 우리가 하고싶은 일을 하기 위한 변명일 뿐이다. 인간은 테크놀로지와 자동화에 본능적으로 매력을 느낀다. 당신이 누군가에게 로봇과 연관이 있다고 말하는 즉시, 그 이야기는 관심을 끌 것이다. 나의 조언자 거스 시아Gus Xia 등의 실험(2016)이 내가 “로봇 효과”라 부르는 것에 대한 증거이다: 한 사람이 어쿠스틱-전자음악 혼합 공연에서 녹음된 오디오와 함께 연주한다고 가정해보자. 어떻게 청중들이 공연에 더 끌리도록 할 수 있을까? 한 가지 방법으로 컴퓨터의 상호작용, 반응유도, 자동반주를 시도해 본다. 그다지 큰 도움이 되지 않는다. 또 다른 방법으로 애니마트로닉스 (영화촬영용 로봇)처럼 인간형 로봇 연주자가 악보를 읽고 연주하도록 해보지만, 이 역시 별 도움이 못된다. 그런데, 컴퓨터 반주와 ‘인터랙티브하게 반응하며 연주’하는 인간형 로봇을 ‘결합’하면 청중은 보다 매력적이고 음악적으로 공연을 즐기게 된다!! 이는 우리가 사람이 하는 일의 자동화에 선천적으로 끌린다는 증거이자, 무엇이 음악을 만드는 것보다 더 인간적일 수 있겠는가?
위의 모든 논의들은 탐구하고 배우려는 기본적인 욕구를 겸비하고 있다. 여기서 변명이나 근거가 진정으로 우리에게 필요한가? 우리의 열정을 따라 나아가고 어디로 가게 되는지 보자. 예술과 과학, 문화에 수많은 성과가 축적된 후에, 더 이상 우리가 옳은 길로 가고 있는지 아닌지 걱정할 필요는 없다. 지금은 우리가 가고 있는 길, 어딘가로 이끌 길을 특징지워보자.
The Computer Music Dream
Taken as a field, Computer Music is following a path that reflects our general understanding of music. First, sound is a critical attribute of music. Thus, from the very beginning, Computer Music was about making sound, combining digital signal processing with digital computation to create musical tones. One could argue the first tones were hardly musical, but through many years of research, our capacity to create musical sounds surely surpassed even the wildest dreams of early researchers.
The second critical attribute of music is organization in time, exemplified by music notation. A great deal of early research concerned musical scores, note lists, music representation and music control. Just as sound synthesis has imitated the centuries‐long development of acoustic instruments, music representation and control research has imitated centuries of development of music notation, from the development of neumes in the 9th century and common practice notation, to graphic notations developed in the last 70 years or so.
Western music assigns importance to both planning by composers and execution by performers, and thus music often has two characteristic representations: the score that represents instructions to performers, and live sound or recordings which convey the performance “product” to listener/consumers. (The same property holds for plays, film, and to some extent architecture and dance). Thus, a third thread of Computer Music research is an exploration and automation of performance, including interaction, expressive interpretation of scores, jazz improvisation, and performance style.
Although highly reductionist, I believe these three threads: sound generation, music representation, and performance serve to summarize our musical knowledge in general and also to describe the development of Computer Music.
컴퓨터 음악에의 꿈
한 분야로서 컴퓨터 음악은 음악에 대한 일반적인 이해를 바탕으로 그 경로를 따라 나아가고 있다. 첫째, “사운드”는 음악에서 결정적인 속성이다. 그러하기에, 아주 초반부터 컴퓨터 음악이란 디지털 신호처리를 디지털 전산과정과 결합하여 음악적인 음으로 바꾸어 내는, 소리를 만드는 것에 관한 것이었다. 누군가는 첫 소리가 음악적이라 보기 어렵다고 반박할 수 있겠으나, 수 년의 연구를 거친 음악적 사운드를 창조하는 우리의 역량은 초반기 연구자들의 가장 원시적이었던 꿈조차 확실히 뛰어넘는 정도이다.
음악의 두번째 중요한 속성은 시간의 재구성으로, 이는 악보로 제시된다. 수많은 초기 연구들이 악보와 음 리스트, 음악적 표현법과 제어법을 다루었다. 소리 합성법이 악기가 수세기 동안 발전해 온 것을 모방하였듯, 음악적 표현 및 제어에 대한 연구는 9세기 네우마와 통례적인 기보법의 발명부터 지난 70여년간 개발되어온 그래픽 기보법까지 수세기간 발전한 기보법을 모방하였다.
서양 음악은 작곡가에 의한 기획과 연주자에 의한 실행, 두 가지 모두에 중요성이 두고 있고, 따라서 음악은 종종 이 “두 가지” 성격의 표현형태가 있다: 연주자에 지시사항을 보여주는 악보와, 청자/소비자에게 ‘생산물product’로서의 연주소리를 전달하는 실시간 사운드나 녹음이다. (연극이나 영화, 일부의 건축물과 무용에도 같은 형태의 산물이 있다.) 고로, 컴퓨터 음악 연구의 세 번째 맥락은 상호작용, 악보의 표현적 해석, 재즈 즉흥연주, 연주 스타일에 이르는, 연주학적 탐구와 그 자동화가 되어야 할 것이다.
꽤 성급한 정리가 되겠으나, 나는 이 세가지 맥락: ‘사운드 생산, 음악적 표현, 연주의 실행’이 우리의 음악적 언어를 대체로 설명하고 컴퓨터 음악의 발전사를 이해하는데 도움이 될 것이라 믿는다.
The Impact of Technology
Throughout the history of Computer Music, the power of computers has grown at an exponential rate. It has been said that an order of magnitude difference is perceived as a qualitative difference, not just a numerical one, so we see a qualitative difference in computing every five to ten years. Each step through punched cards, time‐sharing, personal computers, powerful laptops, cloud computing and mobile devices represents not just an increase in computing power but a new vista of opportunities for artists and researchers as well as a new framework within which we see problems and solutions.
Figure 1 illustrates growth in computing power over the history of Computer Music. The vertical axis is relative power, with a value of 1 assigned to the left‐most year. The best measure of “computing power” is debatable, but all reasonable measures lead to the same conclusions. These graphs are purposefully plotted on a linear scale to show that, compared to today’s computers in 2020, even computers from 2000 seem to have no capability whatsoever. Many believe the growth rate is slowing, so I have plotted the next 30 years with a doubling time of 3 years rather than 2, which is roughly the doubling time since 1960. The horizontal axis on the right is the same, but the vertical axis is reset to so that today’s 1960’s‐relative computing power (2.5E+09) in the first graph appears as 1.0 in the second graph. As this graph shows, todays computers, which power Internet search, face recognition, life‐like computer graphics and of course digital music processing, will seem completely insignificant by 2050. To get even a glimpse of what is in store for the next 30 years, consider that 30 years ago, software sound synthesis was barely possible. (Dannenberg/ Mercer 1992) Or consider that the release of our personal computer audio editor Audacity in 2002 was still a decade away. (Mazzoni/ Dannenberg 2002)
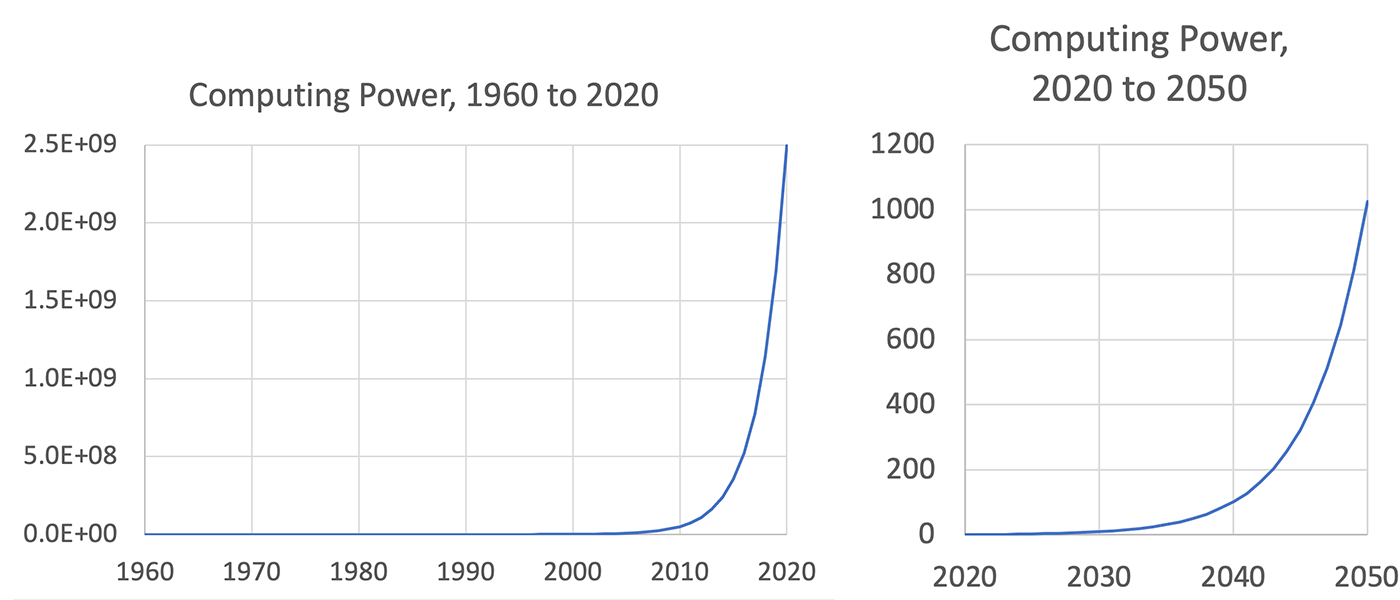
Figure 1. The growth of computing power has followed an exponential curve, doubling roughly every 2 years. Even if the doubling time slows to three years, today's computers will seem primitive within 20 or 30 years. The vertical axes represent relative power, with a value of 1 in 1960 (left) and 2020 (right).
One thing seems certain: We can imagine many developments in terms of today’s technologies and devices, but the technologies of the future will be qualitatively different from what we have now. We will not continue to view problems in the same way. We can think about what we can do with faster computers, but it is much harder to imagine what new forms computing will take when computational power increases by orders of magnitude. We are probably better off to think in terms of musical imperatives.
테크놀로지의 영향
컴퓨터 음악의 역사 내내, 컴퓨터의 역량은 기하급수적인 속도로 성장했다. 어느 정도의 규모 차이는 단순히 수적인 것이 아닌 ‘질적 차이’를 유도하므로, 우리는 매 5년에서 10년마다 컴퓨터 사용에서의 ‘질적 차이’를 목도한다. 천공카드(종이테이프), 타임셰어링(동시사용), 개인컴퓨터, 강력한 노트북, 클라우드 컴퓨팅과 모바일 장비까지 각 단계에서 컴퓨터의 사용도와 성능이 단지 증가하는 것이 아니라 예술가와 연구자들에게 새로운 기회 전망을 보여주고, 문제점과 해결책을 가진 새로운 체계도 마련해 준다.
그림1은 컴퓨터 음악 역사 중 컴퓨팅 역량의 성장을 보여준다. 수직축은 상대적인 역량을 의미하며, 제일 왼쪽 시작 년도가 1의 값이다. “컴퓨팅 역량”에 대한 최적의 측정값은 논란의 여지가 있겠으나, 모든 합리적인 시도는 같은 결과를 가져온다. 이 그래프는 선형적 척도로 그려져, 2020년 오늘날의 컴퓨터와 비교하면 2000년 이후의 컴퓨터 조차도 아무런 성능이 없어 보일 정도이다. 많은 이들이 성장 속도가 둔화하고 있다고 여기는 것 같아서, 나는 향후 30년을 1960년 이래 대략 두 배의 값으로 성장했던 2년 단위 대신 3년마다 두배값이 되도록 그래프를 구성했다. 오른쪽 그래프는 수평축은 동일하나, 수직축은 왼쪽 그래프에서의 오늘날의 1960년 대비 성능값(2.5E+09)을 오른쪽에서는 1.0으로 재설정한 것이다. 이 그래프가 보여주듯, 인터넷 검색, 얼굴 인식, 실제 같은 컴퓨터 그래픽, 디지털 음악 처리도 물론 지원하는 오늘날의 컴퓨터는 2050년에는 완전히 하찮은 존재가 될 것 같다. 향후 30년간 어떤 일이 벌어질 지 어렴풋이라도 알고 싶다면, 30년 전 소프트웨어의 소리 합성이 거의 불가능했었다는 점을 생각해보라. (Dannenberg/Mercer 1992) 혹은 개인용 컴퓨터에 오디오 편집하는 오데시티 Audacity의 2002년 출시가 10년이나 이후라는 점을 고려해보라. (Mazzoni/ Dannenberg 2002)
그림 1. 컴퓨팅 성능은 지수함수 곡선을 따라 성장하였으며, 매 2년마다 대략 두배가 된다. 두 배가 되는 시간을 3년으로 늦추어도, 오늘날의 컴퓨터는 20-30년 내에 원시적인 수준이 될 것이다. 수직축은 상대적인 성능값을 나타내며, 1960년(왼쪽)과 2020년(오른쪽)이 값 1을 갖는다.
한 가지는 확실해진 듯하다: 우리가 오늘날의 기술과 장비에 관하여 여러 발전상을 상상해본다 하더라도, 미래의 기술은 지금의 것과는 ‘질적으로’ 다른 것이 될 것이다. 우리가 문제점을 똑같은 방식으로 대하는 것은 계속되지 않을 것이다. 보다 빨라진 컴퓨터로 무엇을 하게 될지 예상할 수 있을지라도, 자릿수가 다른 속도로 컴퓨팅 성능이 발전한다면 새로운 컴퓨팅이 어떤 모습일지 상상하는 것은 훨씬 어려울 것이다. 음악적 책무에 입각하여 생각해보는 것이 아마 더 나을지도 모른다.
A Brief History of Computer Music
To further explore these threads of sound generation, music representation, and performance, I would like to consider them in the context of some historical Computer Music developments. This is not meant to be a complete history by any means, but it will help set the context for thinking about possible futures.
Early Computer Music
In the earliest years of Computer Music, essentially all computers were mainframe computers that were programmed by submitting a stack of instructions on punched cards and receiving results in print or on magnetic tape. The first music sound generation software is exemplified by Max Mathew’s Music N programs (Mathews M. 1969), which already neatly capture the notions of sound and score (representation) in the “orchestra language” and the “score language.” The former was designed to express digital signal processing needed to create sound, and the latter was a separate music representation language designed to express sequencing and control parameters for those signal processing operations.
Real‐Time Digital Instruments
As soon as integrated circuits achieved enough power to perform basic audio signal‐processing tasks in real time, digital instruments began to appear. Research systems such as the Dartmouth Digital Synthesizer (1973) and the Bell Labs Hal Alles Synthesizer (1976) led to commercial systems such as the CMI Fairlight and New England Digital Corporation Synclavier, which were soon followed by mass‐produced instruments such as the Yamaha DX7(1983). Viewed from the perspective of performance and the understanding of exponential growth in computer power, these developments were inevitable, even though keyboard instruments were qualitatively nothing like the programmed mainframe and minicomputers in use up to that time.
Interactive Systems
The combination of affordable real‐time digital synthesis, the interface possibilities of MIDI, and the introduction of personal computers, all coalescing more‐or‐less in the 1980’s, enabled a new direction in computer music: real‐time musical interaction with computers. (Rowe 1992; Winkler 1998) Many musicians developed interactive systems: Composed Improvisation (Eigenfeldt 2007) by Joel Chadabe, Laurie Spiegel’s “Music Mouse” for personal computers (1986), The Sequential Drum by Max Mathews and Curtis Abbot (Mathews M. V. 1980), Voyager (Lewis 2000) by George Lewis, Ron Kuivila’s compositions with Formula (Anderson/ Kuivila 1990), and David Wessel’s compositions with MIDI‐Lisp (Wessel/ Lavoie, P./ Boynton, L./ Orlarey, Y. 1987) are just a few of many experimental works. In that time period, I designed the CMU MIDI Toolkit in 1984 (Dannenberg 1986), inspired by Doug Collinge’s Moxie (Collinge 1985) language, and created Jimmy Durante Boulevard in a collaboration with Georges Bloch and Xavier Chabot (1989).
Interactive Systems brought compositional algorithms, previously only used for non‐real‐time composition, into the world of performance. Just as real‐time synthesizers can be seen as joining digital sound and performance, interactive systems represent the union of music representation and composition with performance. As mentioned earlier, this created a new mode of composition. The composer specifies a piece not so much by writing notes as by writing interactions. These interactions continuously constrain and guide the sensitive musician to carry out the composer’s plans. At the same time, the improviser is free to inject spontaneous and virtuosic elements that the composer might not have imagined. In the most successful work, a previously unknown and exciting synergy is achieved.
Computer Accompaniment
Another approach to interaction is based on the traditional model of chamber music where notes are determined in a score by the composer, but musicians perform the score with expressive timing. In the Computer Music world, composers were drawn to the possibilities of computation, which fixed music precisely in time, but the only way to combine that approach with live performance was to play along with a fixed recording. There was an obvious disconnect using fixed media in live performance, ignoring the well-developed ideas of expressive performance in chamber music. In 1983, I began to experiment with algorithms, and I built a complete working accompaniment system in 1984 that could listen to my live trumpet performance, follow along in a score, and synthesize another part in real‐time, synchronizing with the soloist. (Dannenberg 1985) Similar work was introduced around the same time by Barry Vercoe.
(1985) Later, my computer accompaniment work was used to create the Piano Tutor, an intelligent tutor for teaching beginning piano students (Dannenberg, et al. 1990), and computer accompaniment was commercialized in what is now SmartMusic and used by hundreds of thousands of students. Work on score following and collaborative performance is still an active topic today.
Human Computer Music Performance
Computer Accompaniment distilled the basic idea of following a score and synchronizing performance, but in music, there are many more problems related to collaboration. This came to my attention around 2005 when I was playing in a rock band’s horn section. As the only trumpet, and not a strong lead player, I began to think how much better it would be if I were the second trumpet alongside a great high‐note player. It did not take long to imagine I could use my computer accompaniment techniques to create a virtual musician for the band. However, I soon realized that the band did not always follow a score strictly from beginning to end. Also, horns do not play all the time, so how would the virtual player enter precisely in time and in tempo without following a leader? A virtual player might “listen” to the keyboard player, but the keyboardist improvises chord voicings and rhythms, so there is no detailed score to follow there.
These and other problems led me to think about musical collaboration much more broadly than before. Synchronization is achieved not only by following scores, but by following the beat, following chord progressions, visual cues, following conductors, becoming the leader, and combinations of these things. Parts are specified by traditional scores, lead sheets, drumming or percussion styles, and analogy (“I want you to play this part the way Bill Evans might do it.”) In other words, the broader goal is not simply an “adaptive sequencer” that synchronizes to a pre‐determined stream of notes, but an artificially intelligent musical partner.
We can see related work in laptop orchestras, networked music performance, and artificial intelligence for composition. These are all approaches that use technology for human‐human and human‐computer music collaboration.
컴퓨터 음악의 간략한 역사
이렇게 사운드 생산, 음악적 표현, 연주 실행으로 이어지는 맥락을 더 깊게 탐구해보기 위하여, 나는 컴퓨터 음악 역사의 맥락에서 몇몇 발전상을 짚어보고자 한다. 어떻든 이는 완전한 역사를 의미하지는 않지만, 미래 가능성을 예견할만한 문맥을 마련해줄 수 있을 것이다.
초기의 컴퓨터 음악
컴퓨터 음악의 초창기 몇 년간은, 모든 컴퓨터가 종이테이프에 한 뭉치의 지시사항을 입력하여 제출하면 인쇄물이나 마그네틱 테이프로 그 결과를 받아 프로그래밍되는 메인프레임 컴퓨터였다. 첫 음악 사운드를 생산하는 소프트웨어는 맥스 매튜스의 뮤직 엔N의 프로그램들이었으며(Mathews M. 1969), 일찍이 사운드와 악보(표현)를 “오케스트라 언어”와 “악보 언어”로 잘 담아내는 것이었다. 전자는 “사운드”를 만드는데 필요한 디지털 신호 처리를 전달하도록 만들어졌고, 후자는 그러한 신호처리를 실행하도록 시퀀싱과 파라미터들을 조절할 수 있게 고안된 별도의 “음악적 표현” 언어로 만들어졌다.
실시간 디지털 악기들
집적회로로 기본적인 오디오 신호처리 업무가 실시간으로 가능하게 되자 곧 디지털 악기들이 나타나기 시작했다. 다트머스 디지털 신서사이저(1973)와 벨 연구소 할 알레스 신서사이저(1976) 같은 연구 시스템에서 페어라이트 CMI와 뉴잉글랜드 디지털사 신클라비어와 같은 상업적 시스템으로 연결되며, 곧이어 야마하 DX7(1983) 같은 대량생산되는 악기도 나오게 되었다. 컴퓨터 성능의 기하급수적 성장에 대한 이해와 함께 ‘연주실행’의 견지에서 보았을 때, 키보드 악기들이 당시에 사용되었던 프로그램된 메인프레임 컴퓨터나 미니 컴퓨터에 ‘질적으로’ 미치지 못했다 할 지라도, 이러한 발전은 불가피했다.
인터랙티브 시스템들
저렴한 가격의 실시간 디지털 합성기기, 미디의 인터페이스 가능성, 그리고 개인용 컴퓨터의 등장, 이들이 정도의 차는 있지만 1980년대 합쳐지면서 컴퓨터 음악의 새로운 동향을 만들어냈다: 즉 컴퓨터로 실시간 음악적 상호작용이 가능하게 되었다. (Rowe 1992; Winkler 1998) 많은 음악가들이 상호작용 시스템을 개발했다: 조엘 차다베Joel Chadabe 의 작곡된 즉흥작품(Eigenfeldt 2007), 로리 슈피겔Laurie Spiegel 의 개인용 컴퓨터를 위한 “뮤직 마우스”(1986), 맥스 매튜스와 커티스 아보트Curtis Abbot의 연속적 드럼The Sequential Drum (Mathews M.V. 1980), 조지 루이스George Lewis의 ‘보이저Voyager‘(Lewis 2000), 론 쿠이빌라Ron Kuivila 의 포뮬라(공식)로 쓴 작품(Anderson/Kuivila 1990), 데이비드 웨슬David Wessel의 미디-리스프MIDI-Lisp로 쓴 작품(Wessel/ Lavoie, P./ Boynton, L./ Orlarey, Y. 1987)은 많은 실험적 작품들 중 일부일 뿐이다. 그 기간에 나는 더그 콜린지Doug Collinge 의 막시Moxie(Collinge 1985) 언어에 영감을 받아 1984년 시엠유 미디도구세트CMU MIDI Toolkit 를 개발했고(Dannenberg 1986), 조르주 블로흐Georges Bloch, 자비에 샤보Xavier Chabot(1989)와 함께 협업하여 지미 듀란트 블러버드Jimmy Durante Boulevard를 창작했다.
상호작용 시스템이 이전에는 비실시간 작곡으로만 사용되었던 작곡 알고리즘을 공연 무대 위로 올려 놓았다. 실시간 신서사이저가 디지털 사운드로 공연 연주에 합류하게 된 것처럼, 상호작용 시스템은 음악적 표현과 작곡 과정, 공연 연주가 연합되었음을 의미한다. 앞서 언급했듯이, 이는 새로운 작곡 양식이 탄생한 것이다. 이제 작곡가는 음표를 기보하는 것이 아니라 상호작용을 만들어 한 작품을 완성한다. 이 상호작용 시스템이 작곡가의 의도를 실행하려 신경쓰는 연주자에게 지속적인 제한과 안내를 제공한다. 이때 즉흥연주자는 자유롭게 작곡가가 계획하지 않은 자발적이거나 기교적인 요소들을 주입할 수 있다. 가장 성공적인 경우, 이전에 없었던 새롭고 흥미로운 동반 상승 효과를 얻을 수 있다.
컴퓨터 동반 연주
상호작용에 대한 다른 관점으로, 전통적인 실내악에서 작곡가가 악보에 음을 결정해두지만 연주자가 이를 표현적인 시간 조절을 하며 연주하는 것에 착안한 것이 있다. 컴퓨터 음악에서는, 고정된 음악으로서 정확한 시간으로 연주하는 계산처리 능력이 작곡가들에게 꽤 매력적이었으나, 실제 연주자들과 함께 연주하려면 그들이 고정매체를 따라 가는 것 외에는 다른 방법이 없다. 전통 실내악에서 잘 발전된 연주 표현 기법들은 무시된 채, 연주자의 실시간 연주와 고정 매체를 사용한 음악 사이에 명백한 단절이 존재하는 것이다. 1983년 나는 알고리즘으로 실험을 시작하여, 1984년 나의 트럼펫 연주를 듣고 악보를 따라 새로운 파트를 실시간으로 합성하며 독주 연주자와 동반으로 연주가 가능한 완전한 형태의 동반연주 시스템을 완성하였다. (Dannenberg 1985) 비슷한 시기에 배리 베르코Barry Vercoe도 이와 유사한 시스템을 발표하였다.(1985) 이후 나의 컴퓨터 동반연주 시스템은 피아노를 처음 시작하는 학생들을 가르치는 지능 튜터인 피아노튜터Piano Tutor를 만드는데 사용되었고 (Dannenberg, et al. 1990), 컴퓨터 동반 연주는 현재 스마트뮤직SmartMusic이라는 이름으로 상업화되어 수십만의 학생들이 사용하고 있다. 악보를 따라가며 협동 연주하는 것에 대한 개발은 지금도 여전히 유효한 연구 주제이다.
휴먼 컴퓨터 음악 퍼포먼스
컴퓨터 동반 연주는 악보를 따르며 연주에 합류한다는 기본 개념을 뽑아낸 것이지만, 실제 음악에서는 합주에 연관된 더 많은 문제점들이 존재한다. 내가 2005년 즈음 록밴드의 금관 파트를 맡아 연주하면서 이 점에 관심을 두게 되었다. 주도적인 연주자가 아닌, 그저 트럼펫 주자로서, 내가 훌륭한 고음파트 연주자와 잘 동반하는 트럼펫 ‘제2주자’라면 얼마나 더 나을 수 있을까 생각하기 시작했다. 오래 지나지 않아 나는 컴퓨터 동반연주 기술을 사용하여 밴드를 위한 가상 연주자를 만드는 상상을 하게 되었다. 하지만, 나는 곧 밴드가 언제나 처음부터 끝까지 악보를 정확하게 따라 연주하지 않는다는 사실을 깨달았다. 게다가, 금관파트가 계속해서 연주하지 않는데, 어떻게 가상 연주자가 지휘도 없이 제 시간에 제 빠르기로 맞추어 합류할 수 있을까? 가상 연주자가 키보드 연주를 “듣는” 것은 가능하더라도, 키보드 연주자가 화음과 리듬을 즉흥으로 연주하는데 이를 따라갈 만큼 상세히 기보된 악보는 없었다.
이런 저런 문제점들로 나는 이전보다 훨씬 더 폭넓게 음악 합동 연주에 대하여 생각하게 되었다. 일치된 연주는 악보를 따라가는 것뿐 아니라 박자를 따라, 화음 진행을 따라, 시각적 신호로, 지휘를 따라, 리드를 하면서, 이것들이 모두 결합되었을 때 가능해지는 것이다. 전통적인 악보, 선율 악보(리드 시트), 드럼이나 타악기 패턴, 유추(“빌 에반스가 연주하듯 이 부분을 연주하시오.”와 같은 말)로 각 파트를 명시한다. 다시 말해, 단순히 미리 정해진 일련의 음들을 동시에 연주하는 “순응적인 시퀀서”가 아니라, “인공지능적인 음악적 파트너”라는 더 폭넓은 목표를 가져야 한다는 것이다.
이와 연관된 작업을 노트북 오케스트라, 네트워크로 연결된 음악 공연, 작곡하는 인공지능에서 볼 수 있다. 이들은 모두 인간 대 인간과 인간 대 컴퓨터 간의 음악 협동 작업에 사용하는 테크놀로지의 접근 방식이다.
Interlude
Let us try to sum up some ideas of this brief discussion. Computer Music has ridden a wave of exponential growth in computing power to get us where we are today. Much of our progress could never happen without integrated circuits, powerful computers and the whole information age (for example, only the pervasive adoption of computing in daily life could drive down price of billion‐transistor processors to affordable levels.) However, the main directions of Computer Music can be seen as an attempt to reproduce and then extend traditional music concerns in three areas: sound, music representation, and performance.
We have discussed an historical progression in which researchers explored the production of sound, music representation and control, real‐time interaction, computer accompaniment, and collaboration in general. The future will bring unimaginable computing technologies
and with them multiple qualitative changes in the way we think about or experience computing. However, our principal musical concerns are likely to be the same ones humans have pursued for centuries if not millennia, so with that assumption let us consider some implications for the future.
막간글
지금까지의 짧은 논의에서 나왔던 생각들을 정리해보자. 컴퓨터 음악은 오늘날의 우리에게 있는 모습대로 기하급수적으로 성장한 컴퓨터 파워의 물결을 타고 전진했다. 우리가 이룬 진보는 집적회로나 고성능의 컴퓨터, 온전한 정보의 시대 없이는 결코 이룰 수 없었을 것들이다. (예를 들어, 일상 생활의 전반에서 컴퓨터를 적용해야만 십 억 개에 달하는 트랜지스터 프로세서의 가격을 적당한 수준으로 낮출 수 있다.) 그러나, 컴퓨터 음악의 주요 방향은 사운드, 음악적 표현, 연주 실행의 세 영역에 대한 전통적인 음악적 요구조건을 재생산하고 확대하려는 시도에 있다.
우리는 역사 속 발전과정에 대하여 논의하였는데, 소리를 생성하고, 음악적 표현과 제어, 실시간 상호작용, 컴퓨터 동반 연주와 협동 작업에 대한 연구가 그 전반적인 것들이었다. 미래는 상상할 수 없을 정도로 컴퓨터 기술이 발전할 것이고, 이에 따라 우리가 컴퓨터에 대해 생각하거나 경험하는 방식에서도 다양한 질적인 변화가 일어날 것이다. 하지만, 음악에 대한 우리의 주요 관심사는, 인류가 수천년은 아니여도 수세기동안 추구해왔던 것과 다름없을 것으로 보이는데, 따라서 이를 전제로 미래에 대한 몇 가지 예측을 해보자.
The Future of (Computer) Music
One way to conceptualize the whole of musical concerns is illustrated in Figure 2. Here we see “Instruments” as the world of sound generation and processing. While instruments produce sounds, musicians organize sounds into phrases, and there is much work to be done to understand phrases (more on this below). Phrases (or, in some terminologies, “musical gestures”) are assembled to form compositions. Compositions are performed, giving rise to many concerns of collaboration and coordination. Let us consider each of these realms separately.
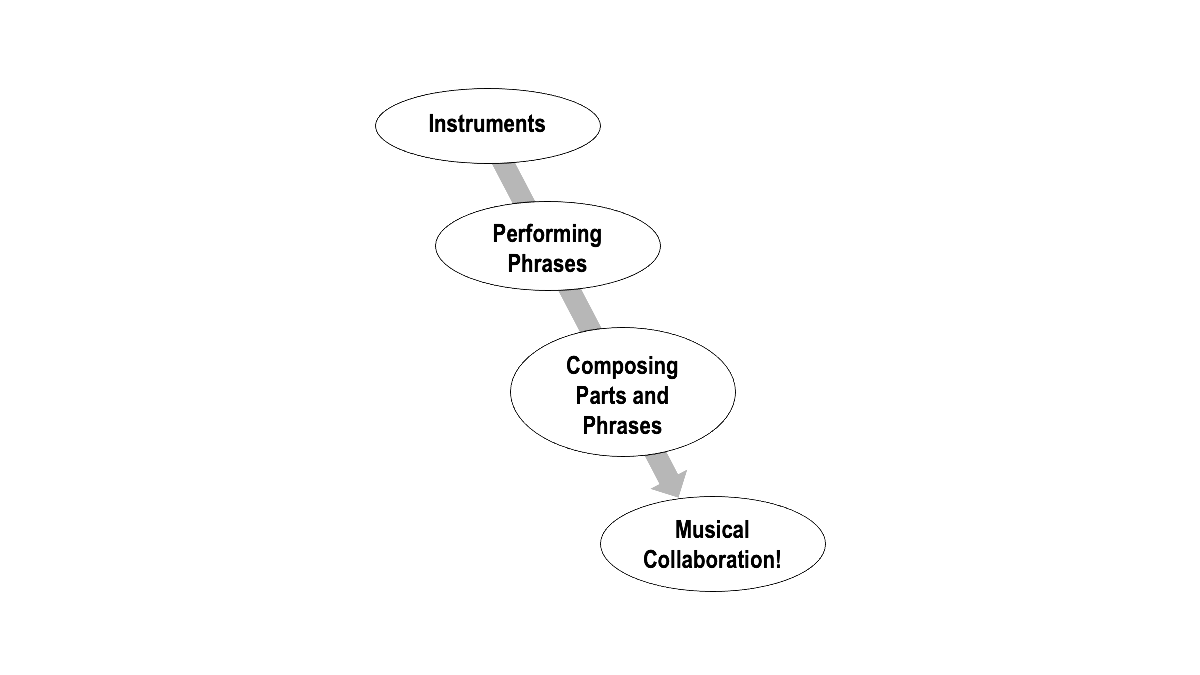
Figure 2.
Schematic of Computer Music areas of concern.
Instruments
Even after decades of research, instrument modeling remains elusive. The non‐linear, 3‐dimensional physics of acoustic instruments are complex (Bilbao 2009), and our perceptual abilities are exceptionally refined, making even slight imperfections quite apparent. Musicians take many years to learn to control acoustic instruments, and without control, even real acoustic instruments do not make interesting musical tones. It seems that in the future, orders of magnitude more computation will be applied to acoustic instrument simulation as well as to machine learning to discover how to control them to produce musical results. From there, new possibilities will emerge to artistically manipulate “physics” in our simulations to design new instruments and new sounds, informed but not limited by real acoustics. Spectral synthesis models based on computational models of perception are also a promising direction for new sound creation.
Another interesting direction is the development of physical robotic instruments such as those explored by Trimpin, Eric Singer, Ajay Kapur and others. I helped Ben Brown and Garth Zeglin construct a high‐performance robot bagpipe player, McBlare, at Carnegie Mellon University. (See Figure 3.) The “robot effect” described earlier suggests that we should pay attention to robots, and particularly humanoid robots such as Waseda’s flute playing machine WF‐2 (Solis, J., et al. 2006). Just as musicians have been able to use computers and sensors developed for other applications, I expect humanoid robots created with other purposes in mind will offer very engaging modes of musical performance.
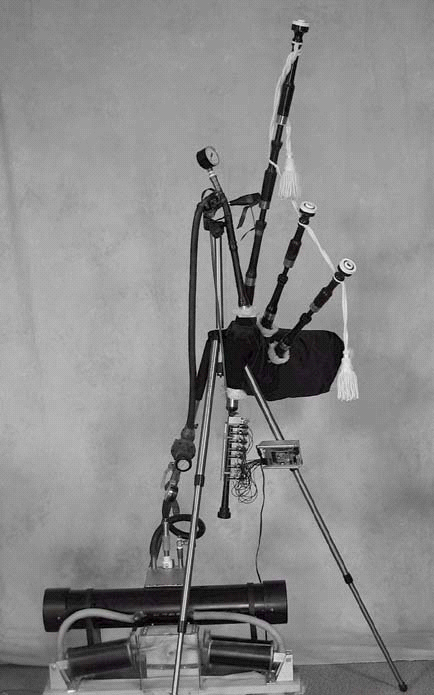
Figure 3.
McBlare, Carnegie Mellon's robotic bagpipe player.
Phrases
Many years ago, the mantra “sampling is dead” was frequently heard among computer music researchers. The basic idea of samples is to record “notes” of instruments and play them back on demand. If a violin plays a range of 4 octaves at 10 different dynamic levels, that is about 500 sounds, assuming we can find reasonable ways to control duration and simulate vibrato. In the early days of limited memory, even having 50 very short samples that required “looping” to extend them was already expensive, so it seemed hopeless to achieve high quality through sampling. Over time, however, memory prices came down, so sample libraries could add longer samples and many variations of articulation, bow position, and even extended techniques. It seems that our predictions were premature.
However, expressive continuous control is still a problem for samples, and here is where phrases enter the picture. My work in the 90’s showed that the details of individual notes are highly dependent upon context. (Dannenberg/ Pellerin/ Derenyi 1998) For example, a slurred transition between two trumpet notes is entirely different from an articulation where the air is briefly stopped by the tongue, and details of the transitions are also affected by the pitches of the notes. Thus, phrases are critical units for musical expression and even timbre, yet they have been largely ignored.
In the future, either sampling will have to “die” or expressive phrases available to string and wind players will disappear from electronic music. Well, at least we will have to solve the problem of sample selection from evergrowing libraries that now reach gigabytes, and we will have to do something about the rigidity of recorded samples once they are selected. There is certainly room for more research here. As storage limits disappear, the real limits of sampling are becoming apparent, and old solutions such as work from my lab on Spectral Interpolation Synthesis (Dannenberg/ Derenyi 1998) and other work on physical models are re‐emerging. Eric Lindemann’s Synful Orchestra synthesis technology is a commercial example of a more phrase‐based and non-sample‐based approach.
Composing in the Future
Recently, there has been a resurgence of work on automated computer music composition. Every innovation in Artificial intelligence – rule‐based expert systems, constraint systems, production systems, Bayesian approaches, neural networks and now various kinds of deep learning – has been applied to model the compositional process. We can expect this trend to continue.
In my view, recent work, while technically impressive, has been musically disappointing. Perhaps the success of deep networks in other areas has misled researchers into putting too much faith in data‐driven learning methods. Composition is regarded by many as a problem of imitation: Train a machine learning algorithm with examples of music and try to generate something similar. But how many composers aim to (merely) imitate? Composers have not played a large role in recent research, and in many ways, earlier research by composers produced more musical results. Composers have a better understanding of what composition is really about, and it seems that deep learning is no substitute (yet) for human understanding. One possible direction for the future is the development of a real science of composition involving investigations in neuroscience, models of information and communication, participation by composers, and listener studies. Then again, with another 10 years’ growth in computational power and the qualitative changes it will bring, we could see a revolution in scientific practice that makes even these ideas seem short‐sighted.
In any case, there is clearly room for more research here, and we can expect to see a slow and steady progression beginning with simpler tasks such as making drum loops, harmonization and creating musical textures. From there, perhaps we will develop composition systems that work well in highly constrained settings: improvising over a set meter and chord progression, composing percussion tracks or bass lines given a set of parts, or generating call‐and‐response melodic units. Eventually, we will come to understand higher‐level structures, music anticipation and surprise, and music design to the point we begin to see truly original musical creations by computer.
Performance in the Future
Live performance with computers is still nascent. There are some stunning pieces in the repertoire, and plenty of techniques from composed improvisation to computer accompaniment, but let us be honest and critical here. Interactive systems are largely based on triggers to step through fixed sequences, simple responses to simple input patterns, or just random but interesting choices. Machines have little understanding of tempo, timbre, form, anticipation or surprise, and it is as much a stretch to call computers true collaborators in 2020 as it would be to call the pianoforte a musical collaborator in 1750.
Computer accompaniment systems coordinate with musicians at a finer time scale by tracking performances note‐by‐note. Work with Gus Xia shows that deeper musical understanding can dramatically improve prediction in collaborative performance. (Xia/ Wang/ Dannenberg/ Gordon 2015) So far, computer accompaniment systems are quite shallow and fail to adapt as collaborators might. These systems are also brittle, typically applying only one method of listening or processing input, whereas musicians have a much richer repertoire of techniques including score analysis, phrase analysis, entrainment to beats, leading and following, giving and accepting visual cues, source separation, and exceptional musical awareness.
One of my research directions is to enable human‐computer collaboration in the performance of beat‐based music, an area largely ignored by Computer Music research. It is not clear who would actually perform with such systems, but it is an interesting challenge. In any case, we have a long way to go to develop more computational music understanding for live collaborative music performance.
(컴퓨터) 음악의 미래
음악에 대한 관심사 전체를 개념적으로 정리한 것을 그림2에 나타내었다. 여기서 “악기instruments”는 소리를 생성하고 처리하는 하나의 세계를 뜻한다. 악기가 소리를 만드는 동안, 음악가는 소리를 조합하여 악구phrase로 만드는데, 이 악구를 이해하려면 많은 과정이 필요하다 (이에 대한 더많은 정보를 다음 쪽을 참고하라). 악구(혹은, 다른 용어로는 “음악적 제스처”)가 조립되어 작곡 작품을 형성한다. 작품이 연주되면서, 합주나 협업에 대한 여러 문제점들이 생기게 된다. 각각의 영역을 개별적으로 고려해보자.
그림 2.
컴퓨터음악의 중요한 영역을 도식으로 나타낸 것.
악기
수십년의 연구에도 불구하고, 악기 모델화는 여전히 실행이 어려운 단계이다. 음향 악기의 비선형, 3차원적 물리학은 복잡하고(Bilbao 2009), 사소한 결함도 명확히 느껴질 만큼
우리의 지각능력은 유난히도 정교하다. 음악가들이 악기를 다루는 법을 배우는 데는 수년이 걸리고, 제어 능력이 없이는 실제 악기로도 그럴싸한 음악적인 소리를 만들기 어렵다.
미래에는 음악적 결과를 내기 위해 어떻게 악기를 제어해야 하는지 알아내기 위해 훨씬 많은 계산처리 과정이 기존 악기의 시뮬레이션이나 머신 러닝에 적용될 것이다. 거기서부터, 새로운 악기와 새로운 사운드를 만드는 시뮬레이션 과정에서 “물리학”을 예술적으로 통제할 수 있는, 실제 음향학에 국한되지 않은 새로운 사실과 함께, 새로운 가능성이 나타나게 될 것이다. 인지적 연산 모델에 기반한 스펙트럼 합성 모델도 역시 새로운 사운드를 만드는데 유망한 방향의 연구 분야이다.
또 하나 흥미로운 분야는 트림핀Trimpin, 에릭 싱어Eric Singer, 아제이 카푸르Ajay Kapur 외 다수가 시도한 것과 같은 실체적 로봇 악기의 개발이다. 나는 카네기멜론 대학에서 벤 브라운Ben Brown과 가드 제글린Garth Zeglin을 도와 고성능 로봇 백파이프 연주자인 맥블레어MacBlare를 제작했다. (그림3을 보라.) 앞서 설명한 “로봇 효과”는 우리가 로봇에, 특히 와세다의 플룻 연주 기기 WF‐2 (Solis, J., et al. 2006)와 같은 ‘인간형’ 로봇에 주의를 기울여야 한다는 것을 알려준다. 음악가들이 다른 응용 분야를 위해 개발된 컴퓨터와 센서를 사용할 수 있게 된 것 처럼, 나는 다른 목적을 염두에 두고 만들어진 인간형 로봇이 아주 매혹적인 음악 연주 스타일을 만들어낼 날이 오길 기대한다.
그림 3.
맥블레어, 카네기멜론의 로봇식 백파이프 연주자.
악구
수 년 전, “샘플링은 끝났다”라는 주문이 컴퓨터음악 연구자들 사이에서 자주 들렸다. 샘플의 기본 개념은 악기의 “음”들을 녹음하고 필요에 따라 그것을 재생하는 것이다. 바이올린이 네 옥타브의 음역을 열 단계의 셈여림으로 연주하면 약 500개의 소리가 되고, 우리는 이를 적당한 방법으로 길이를 조절하고 비브라토를 적용할 수 있을 것이다. 메모리가 제한적이었던 초기 시절에는, 오 십 개의 매우 짧은 샘플 조차도 필요한 만큼 “연속재생”하여 이들을 늘이는데에 이미 많은 비용이 소요되었기 때문에, 샘플링으로 고품질의 소리를 얻는 것은 기대하기 어려웠다. 그러나 시간이 흘러, 메모리 가격이 낮아지고, 샘플 저장소에 더 긴 샘플과 다양한 아티큘레이션, 활 포지션, 여러 확장된 기법의 소리를 추가할 수 있게 되었다. 우리의 예측은 시기상조였던 것으로 보인다.
그런데, 지속적인 표현 제어는 여전히 샘플의 문제점이고, 여기가 바로 ‘악구’가 등장해야 하는 지점이다. 90년대 내 연구에서 각 개별 음의 세세한 요소들이 문맥에 따라 민감하게 변화함을 보여준다. (Dannenberg/ Pellerin/ Derenyi 1998) 예를 들어, 이음줄로 연결된 두 개의 트럼펫 음은 텅잉(혀)으로 소리가 끊어지는 기법과는 전혀 다르게 표현되며, 두 음이 연결되는 지점 또한 음의 높이에 따라 다르게 표현된다. 따라서, ‘악구’에서는 음악적인 표현법과 음색도 중요한 결합 요건이 되지만, 대부분 이러한 점에 주의를 기울이지 않는다.
미래에는, 전자 음악에서 샘플링이 “무용지물”이 되거나 관현악기 연주자들의 표현적인 악구가 사라져야 할 것이다. 아마, 적어도 현재 기가바이트에 달하는 전례없이 성장하는 저장소로 샘플 선택의 문제점을 해결하고, 일단 선택된 녹음 샘플의 비유연성에 대해 무슨 대책이라도 세워야 할 것이다. 여기 더 많은 연구를 위한 여지는 확실히 있다. 저장의 한계가 없어지면, 샘플의 진짜 한계점이 분명해지고, 내 실험실에서의 스펙트럼 보간 합성에 대한 연구(Dannenberg/ Derenyi 1998)나 다른 물리적 모델에 대한 연구의 지난 해결책들이 다시 부상하게 될 것이다. 에릭 린드만Eric Lindemann의 신풀Synful 오케스트라 합성 기술은 보다 악구에 기반하며 샘플로 접근하지 않는 상업적 예시가 된다.
미래의 작곡하기
근래에, 컴퓨터 음악 작곡 자동화에 대한 연구가 다시 부활하고 있다. 모든 인공지능에서의 혁신 – 규칙기반의 전문가 시스템, 제한적 시스템, 생산적 시스템, 베이지안 접근법, 신경망 네트워크와 현 시점의 다양한 딥 러닝 – 이 작곡 과정을 모델화하는데 응용되고 있다. 이러한 경향은 지속될 것으로 보인다.
내 생각에, 최근 작업들은 기술적으로는 돋보이나 음악적으로는 실망스럽다. 다른 분야에서 깊이있는 성공적 네트워크 작업이 아마 연구자들에게는 데이터 기반의 러닝 방식에 지나친 믿음을 주었을 것 같다. 작곡은 많은 이들이 모방의 범주로 받아들여져서: 음악작품을 예시로 삼아 머신 러닝 알고리즘를 돌리면서 그와 비슷한 결과를 얻으려 한다. 그러나 얼마나 많은 작곡가들이 (단지) 모방에 그치고자 하는가? 작곡가들은 최근 연구에서 큰 역할을 하지 못했으며, 여러 관점에서 오히려 초반기 작곡가들의 연구가 보다 음악적인 결과를 얻었다. 작곡가들은 작곡의 본질에 대해 나은 이해력을 갖고 있고, 딥 러닝이 (아직은) 사람의 이해에 미칠 대체물이 될 수는 없는 것 같다. 미래에 가능할 만한 분야는 신경과학적 조사, 정보와 커뮤니케이션을 위한 모델, 작곡가의 참여, 청중 연구와 연관된 현실 과학적 작곡의 개발이다. 그러하여 다시 말하면, 앞으로 올 향후 십년 간 처리능력과 질적 변화의 성장으로, 이러한 예측조차 근시안적으로 만들만한 과학적 실체의 혁명을 볼 수 있을 것이다.
어떠한 경우에든, 여기 더 많은 연구의 여지가 분명히 있으며, 우리는 드럼 루프를 만들거나, 화음을 쌓고 성부 짜임새를 구성하는 것과 같이 보다 간단한 작업에서 시작하여 더디지만 꾸준히 진행해 나가야 한다. 거기서부터, 박자 변화와 화음 진행에 따라 즉흥 연주를 하고, 전체 짜임새에 어울리는 타악기 파트나 베이스 성부를 만들고, 선율을 주고받으며 작곡하는 식의, 높은 수준으로 제한된 설정도 잘 처리할 수 있는 작곡 시스템을 만들어낼 수 있을 것이다. 결국, 우리가 더 복잡한 구성, 음악적 기대와 서프라이즈, 뮤직 디자인을 제대로 이해하게 될 때가, 진정으로 독창적인 컴퓨터 작곡을 하는 시점이 될 것이다.
미래의 연주
컴퓨터로 하는 라이브 공연은 아직 초기단계이다. 작품목록에 멋진 곡들이 있고 즉흥 프로그램부터 컴퓨터 동반 연주까지 많은 기술들이 있긴 하지만, 여기서는 솔직하게 비판해보자. 상호작용 시스템은 대체로 트리거를 사용하여 정해진 시퀀스들을 차례로 실행하거나, 간단한 입력 패턴에 간단한 반응을 연결하고, 흥미로운 어떤 것들을 무작위로 선택하는 방식이다. 기계는 빠르기나 음색, 형식, 음악적 기대감과 서프라이즈를 잘 모르는데, 1750년 피아노를 음악적 협력자라 불렀던 것처럼 컴퓨터는 2020년 진정한 협력자라 부르는 것은 무리가 있다.
컴퓨터 동반연주 시스템은 연주자가 음표 하나하나 연주하는 것을 미세한 시간 단위로 트래킹하면서 이루어진다. 거스 시아와의 동반연주 작업에서, 음악에 대한 더 깊은 이해를 바탕으로 추정하였을 때 결과가 극적으로 향상됨을 알 수 있었다. (Xia/ Wang/ Dannenberg/ Gordon 2015) 지금까지의 컴퓨터 동반연주 시스템은 매우 얕은 정도로, 협력자의 수준으로 받아들여지지는 못했다. 이 시스템은 취약하기도 한데, 실제 음악가가 악보와 악구를 분석하고, 비트를 타고, 리드하거나 따라가고, 시각적 신호를 주거나 받고, 음원을 분리하고, 특별한 음악적 인식을 하는 등 매우 다각적인 테크닉을 구사하는데 반해, 이 시스템은 듣거나 입력을 처리하는 한 가지 방식만 적용 가능하다.
비트 기반의 음악을 인간과 컴퓨터로 함께 연주 공연하는 것이 내 연구 주제 중 하나인데, 이 영역은 컴퓨터 음악 연구에서 별로 관심을 두지 않는 곳이다. 이러한 시스템을 실제로 누가 쓰게 될 지는 모르지만, 흥미로운 도전이라 여긴다. 어쨌든, 컴퓨터와 실시간으로 협동하여 음악을 공연하는데 필요한 보다 전산적인 이해력을 갖추려면 갈 길이 멀다.
Non‐Traditional Music
In considering music through the lens of historical constants, we should not conclude that computers are simply a way to preserve past traditions or to electronically reproduce the past. This is certainly what we have seen in the first commercial waves of computer music technology, including synthesis of acoustic instrument sounds, electronic keyboards for performance, and music representations such as MIDI, which is based on traditional concepts of notes, scales and beats.
Even though I believe computer music developments and perhaps even the future can be seen in traditional terms of sound, representation, and performance, this does not mean that we are stuck with traditional sounds, conventional representations, or the “individual musicians control independent instruments in coordinated, co‐located ensembles” approach to music performance. Many of these traditions were being challenged even before computing entered the scene.
Consider Conlon Nancarrow’s “Study for Player Piano No.1” (1951), an early work in a series of compositions that inspired many computer music composers, or Krzysztof Penderecki’s “Threnody to the Victims of Hiroshima” (1960), which uses traditional instruments (orchestral strings) but non‐traditional playing techniques, pitches, rhythmic concepts, and arguably has no sounds identifiable as “notes.” Many 20th Century works including these established foundations for Computer Music composers. Nevertheless, these works can still be seen in terms of instruments (the player piano or string orchestra), representation (piano rolls, graphical scores) and performance (in these examples, both fairly traditional).
Composers of the early 20th Century “broke the rules” to find a way forward, and computers give us even more opportunities to redefine the parameters, conventions and practice of music. This trend has been amplified by the democratization of music creation and distribution. With the low cost of computing, music creators are no longer dependent upon the power structures of orchestras, opera companies, or even studios to realize their ideas. The Internet has created new ways to reach audiences. Thus, we are now in a period of great exploration that seems likely to continue.
비전통적 음악
역사적 불변이라는 렌즈로 음악을 볼 때, 컴퓨터를 단순히 과거의 전통을 보존하는, 혹은 전자적으로 과거를 재생산하는 수단으로 결론지어서는 안된다. 이는 음과 음계, 박자 같은 전통적인 개념에 기반하여 음향 악기 사운드를 합성하고, 공연에서 전자키보드를 쓰고, 미디 같은 음악적 표현법을 활용하면서 컴퓨터 음악 기술이 처음으로 상업적인 파도를 탔을 때 확실히 본 것이다.
나는 컴퓨터 음악의 발전, 그리고 그 미래도 사운드와 표현, 연주라는 전통적인 요구조건에 달려있다고 믿지만, 이것이 전통적인 사운드와 기존의 표현기법, 그리고 “개별 연주자들이 독립적으로 자신의 악기를 연주하며 동일한 공간에 위치한 앙상블과 협력하는” 방식의 음악 연주에 머물러야 한다는 뜻은 아니다. 이러한 전통 중 많은 부분은 컴퓨터가 등장하기 전에 이미 위기를 겪고 있었다.
콘론 낸캐로우의 “자동피아노를 위한 스터디 1번”(1951)은 많은 컴퓨터음악 작곡가들에게 영감을 준 시리즈 작품의 초기작이며, 크시슈토프 펜데레츠키의 “히로시마 희생자를 위한 애가”(1960)는 전통악기(현오케스트라)를 위한 곡이지만, 비전통적인 연주기법과 음고, 리듬개념을 사용했고, 논란의 여지는 있겠으나 “음”으로 들리는 소리가 아예 없는 작품이다. 이들을 포함하여 많은 20세기 작품들이 컴퓨터음악 작곡가들을 위한 기반을 마련해주었다. 그럼에도 불구하고 이러한 작품들을 여전히 기악을 위한 (자동피아노나 현오케스트라), 표현기법과(피아노 롤, 그래픽 스코어), 연주형태(이들의 예에서는, 둘 다 상당히 전통적인)에 의한 것으로 해석할 뿐이다.
20세기 초반의 작곡가들이 “규칙을 깨고” 앞으로 나아갈 길을 탐구했다면, 지금 우리는 컴퓨터로 음악의 각 요소(파라미터)와 기존의 관례와 관행을 재정의할 기회가 있다. 음악의 창작과 배포의 민주화로 이러한 경향은 더욱 확장되는 중이다. 컴퓨터로 인해 소요 비용이 낮아졌기 때문에, 음악창작자는 더 이상 그들의 아이디어를 실현해 줄 오케스트라나 오페라단, 스튜디오의 권력 구조에 의존하지 않아도 된다. 인터넷이 청중에게 접근할 수 있는 새로운 방법을 열어주었다. 즉, 우리는 지금 오래도록 계속될 대탐험의 시대에 있다.
A "Moonshot Project" for Computer Music
My colleague Rowland Chen created an interesting challenge that I believe exemplifies the current problems in Computer Music research. (Chen/ Dannenberg/ Raj/ Singh 2020) Just as the goal of putting a man on the moon stimulated an array of technical advances in space exploration, with wide‐ranging and important spin‐offs, I believe a good “moonshot” project might stimulate and stretch Computer Music research.
Jerry Garcia was a founding member of the Grateful Dead. He is dead, but millions of fans miss him, and thousands of hours of live recordings survive. What if we could create a faithful imitation of Jerry Garcia? The problems we would have to solve span the range of Computer Music concerns, including:
∙ Sound: Model Garcia’s electric guitar sounds, including effects, amplifier distortion and sound propagation. Vocal sounds seem even more difficult.
∙ Control: Isolated guitar sounds are not enough. Perceived sound is influenced by articulation, bends, vibrato, frets and fingerings, all of which are time‐varying, constrained by physics, the neuro‐musculature system and mutual depende-ncies. Again, the singing voice is yet more difficult.
∙ Composition: The Grateful Dead are known for long improvisations and launching the “jam band” movement. One would expect a “Jerry Garcia” model to create new improvisations with long‐term coherence, interaction and collaboration with human bandmates and faithful adherence to style. (Perhaps a continuing evolution of style is also necessary to keep fans interested and to justify new performances.)
∙ Collaboration: Part of the essence of the Grateful Dead is the collaboration among the band members in constructing extended “jams.” Musical coordination exists at all levels from beat‐ and measure‐level synchronization to larger sections and transitions.
∙ In order to accomplish all this, it seems necessary to greatly extend the state‐of‐the‐art in machine listening, especially source separation techniques. If we could isolate instruments in the 10,000 hours of Grateful Dead concert recordings that are available for study, we would at least have a wealth of interesting data. Even with that data, we need advances in the analysis of structure and style in those performances.
Whether we actually embark on a “moonshot” project, it is a good practice to set goals and to dream big. In my experience, real objective musical goals are invaluable in setting the research agenda.
컴퓨터 음악을 위한 "문쇼트" 프로젝트
나의 동료 로랜드 첸Rowland Chen은 컴퓨터 음악연구의 현 문제점을 짚는, 내가 믿기로 흥미로운 과제에 도전하였다. (Chen/ Dannenberg/ Raj/ Singh 2020) 사람이 달에 간다는 목표가 우주 탐험에의 기술적 진보를, 광범위하고 중대한 파생적 효과까지 낳으며 줄줄이 이루도록 한 것 같이, 괜찮은 “문쇼트” 프로젝트가 컴퓨터 음악 연구를 활발하게 하고 길게 지속시킬 수 있으리라 생각한다.
제리 가르시아Jerry Garcia는 그레이트풀 데드Grateful Dead[20세기 후반 미국의 상징적인 록밴드]의 창립맴버였다. 그는 죽었지만, 수백의 팬이 그를 그리워하고, 수천 시간의 음반이 남아있다. 제리 가르시아를 충실히 모방하는 프로그램을 만들 수 있다면 어떨까? 우리가 해결해야 할 문제는 다음 사항을 포함하여 컴퓨터 음악의 범주에 있다.
∙ 사운드: 가르시아를 모델로 하는 전자 기타 사운드, 이펙트와 증폭왜곡(앰프 디스토션), 소리전파(사운드 프로퍼게이션)를 포함한다. 보컬 사운드는 훨씬 더 어려워 보인다.
∙ 컨트롤: 순수한 기타 사운드로는 충분치 않다. 아티큘레이션, 벤딩, 비브라토, 프렛과 핑거링의 적용이 있어야 하고, 이들 모두 시간에 따라 유동적이며, 물리학과 신경-근육 시스템, 상호 의존성에 따른다. 다시 말하지만, 노래하는 목소리는 여전히 더 어렵다.
∙ 작곡: 그레이트풀 데드는 긴 즉흥연주와 “잼 밴드”라는 부분으로 시작하는 것으로 유명하다. “제리 가르시아” 모델이 장시간 일관되게, 상호작용하며 인간 밴드동료들과 충실히 스타일을 지키면서 새로운 즉흥연주를 해야 할 것이다. (아마도 스타일의 지속적인 진화도 팬들의 관심을 유지하고 새로운 공연을 정당화하는데 필요할 것이다.)
∙ 협업: 그레이트풀 데드의 핵심 중 하나가 “잼”을 구성하여 확장시켜 나갈 때 밴드맴버들 사이의 협동 작업이다. 음악에서의 협동은 한 박, 한 마디 단계로 일치시키는 것부터 보다 큰 섹션과 전환까지 모든 수준의 단계에서 존재한다.
∙ 이것들을 모두 달성하려면, 기계의 청취 능력을, 특히 음원을 분리하는 기술을 최고의 수준으로 크게 강화해야 할 것이다. 연구에 쓸 수 있는 1 만 시간의 그레이트풀 데드 콘서트 녹음자료에서 각 악기 소리를 분리해내기만 해도, 충분한 정도의 흥미로운 데이터를 갖게 되는 것이다. 그 데이터만 놓고 봐도, 그러한 공연 연주에서의 형식과 스타일을 분석하는 기술의 개발도 필요하다.
우리가 “문쇼트” 프로젝트에 실제로 착수하든 간에, 목표를 설정하고 큰 꿈을 꾸는 것은 좋은 행동이다. 내 경험상, 정말로 객관적인 음악적 목표는 연구 의제를 설정하는 데 매우 가치있다.
Conclusions
If we stand back far enough, we can see Computer Music as a grand undertaking to understand and automate every aspect of music making, with a clear progression:
∙ From primitive sound generation and reproduction, we have learned to create new sounds. Research continues to explore new sounds as well as to create better models for known acoustic sounds in all their richness and complexity.
∙ Beginning with simple event lists and other score‐like representations, we have developed more complex and dynamic control approaches, leading to imitative computer‐generated compositions and to interactive, responsive music systems.
∙ From early performances with fixed media, we have developed computer accompaniment systems, responsive robot musicians, and we have begun to study collaborative music making in greater generality.
I believe these trends help us to anticipate what the future will bring: Richer sounds and better synthesis models, better understanding for building higher‐level musical forms from phrases to entire music compositions, and more sophisticated approaches to collaborative music making between humans and machines.
While these themes seem to be predictable, the exponential growth of computing power makes the details hard to even imagine, and we should expect qualitative changes on par with the shift from mainframes to laptops or books to Internet. These changes will continue to surprise us, but they will also open new and interesting avenues to pursue our goals.
Ultimately, our attraction to modeling, automation and computation in music is driven by the natural human urge to explore and learn. Let us hope that through this experience of constructing knowledge, we also learn to use it wisely for the benefit and enjoyment of society.
Acknowledgements
I wish to thank the KEAMS organizers for the occasion to organize these thoughts. My work would not be possible without the support the School of Computer Science at Carnegie Mellon University and my many stellar colleagues and students, from whom I have learned so
much. Throughout this paper, I have referenced particular papers I had in mind, but I also mention areas full of great contributions by many additional researchers. I believe a quick Internet search with obvious keywords will lead you to their papers, and I hope dozens of authors will forgive me for omitting references to their work here. I have certainly learned a lot from my Computer Music colleagues, whose friendship over the years continues to make this a great journey.
결론
한걸음 뒤로 물러나 충분히 생각해본다면, 컴퓨터 음악이란 음악을 만드는 데 ‘모든’ 면모를 이해하고 자동화하는 웅대한 사업이며, 다음과 같은 명백한 진전이 있음을 알게 될 것이다
∙ 초기의 사운드 생성과 재생 과정부터 새로운 소리를 만드는 방법을 학습해 왔다. 계속해서 새로운 소리를 탐구하고, 풍부함과 복잡함을 갖춘 기존의 음향 사운드를 보다 잘 따르는 모델을 구축하는 연구도 지속된다.
∙ 간단한 이벤트 목록이나 악보와 비슷한 다른 표현법을 시작으로, 더 복잡하고 역동적인 제어 방법을 개발하고 있으며, 컴퓨터로 생성하는 모방적 작곡과 상호작용적, 반응형의 음악 시스템으로 이어져오고 있다.
∙ 고정 매체를 사용한 초기의 공연 연주부터, 컴퓨터 동반연주 시스템, 반응하는 로봇 음악가를 개발하였으며, 더 큰 일반성을 갖는 협동 음악 창작에 대한 연구도 착수하였다.
이러한 동향을 살펴보는 것이 미래에 무엇을 얻게 될지 예견하는 데 도움이 될 것이라 믿는다: 더 풍부한 사운드와 더 나은 합성 모델, 악구부터 전체 작품까지 더 높은 수준의 음악형식 구성을 더 잘 이해하고, 인간과 기계가 협동하며 음악을 작곡하는 데 더 세심한 접근방법이 그것이다.
이러한 주제들이 예측가능한 것으로 보이겠지만, 컴퓨팅의 기하급수적 성장이 세세한 사항은 상상조차 어렵게 만들기 때문에, 메인프레임에서 노트북으로, 책에서 인터넷으로 전환된 것과 동등한 수준의 ‘질적’변화를 예상해야 한다. 이러한 변환은 항상 우리를 놀라게 하지만, 우리를 목표를 이뤄줄 새롭고 매력적인 길도 열어줄 것이다.
궁극적으로, 음악에서의 모델화와 자동화, 전산처리에 이끌림은 탐구하고 학습하고자 하는 자연적인 인간의 욕구에 의한 것이다. 이렇게 지식을 쌓는 경험을 하고 이를 사회의 이익과 즐거움을 위해 현명하게 활용하는 방법도 배우기를 희망한다.
감사의 말
이러한 생각을 정리할 기회를 준 한국전자음악협회 주최측에 감사를 전한다. 카네기멜론 대학 컴퓨터공학과와, 많은 것을 가르쳐준 나의 뛰어난 동료와 학생들의 지원 없이는 이 일이 불가능했을 것이다. 이 글 전체에 걸쳐, 내가 염두에 두었던 특정 논문들을 참고로 활용했을 뿐 아니라, 많은 다른 연구원들이 크게 기여한 분야들도 언급했다. 명확한 주제어와 빠른 인터넷 검색으로 그 논문들에 접근할 수 있으리라 믿으며, 참고목록에서 생략하게 된 수십 명의 저자들에게는 양해를 구한다. 나는 나의 컴퓨터음악 동료들에게서 많은 것을 배웠고, 그들과의 오랜 우정이 훌륭한 여정으로 계속되고 있음을 밝힌다.
References
Anderson, D. P./ Kuivila, R. (1990). A System for Computer Music Performance. ACM Transactions on Computer Systems 8(1): 56‐82.
Bilbao, S. (2009). Numerical Sound Synthesis: Finite Difference Schemes and Simulation in Musical Acoustics. Wiley.
Block, G./ Chabot, X./ Dannenberg, R. (1989). Jimmy Durante Boulevard. On Current Directions in Computer Music Research (CD‐ROM). Cambridge, MA: MIT Press.
Chen, R./ Dannenberg, R./ Raj, B./ Singh, R. (2020). Artificial Creative Intelligence: Breaking the Imitation Barrier. Proceedings of the 11th International Conference on Computational Creativity: 319‐325. Association for Computational Creativity.
Collinge, D. J. (1985). MOXIE: A Language for Computer Music Performance. Proceedings of the International Computer Music Conference 1984: 217‐220. San Francisco: International Computer Music Association.
Dannenberg, R. (1985). An On‐Line Algorithm for Real‐Time Accompaniment. Proceedings of the 1984 International Computer Music Conference: 193‐198. San Francisco: Computer Music Association.
Dannenberg, R. (1986). The CMU MIDI Toolkit. Proceedings of the 1986 International Computer Music Conference: 53‐56. San Francisco: International Computer Music Association.
Dannenberg, R./ Derenyi, I. (1998). Combining Instrument and Performance Models for High‐Quality Music Synthesis. Journal of New Music Research 27(3): 211‐238.
Dannenberg, R./ Mercer, C. (1992). Real‐Time Software Synthesis on Superscalar Architectures. Proceedings of the 1992 International Computer Music Conference: 174‐177. International Computer Music Association.
Dannenberg, R./ Pellerin, H./ Derenyi, I. (1998). A Study of Trumpet Envelopes. Proceedings of the International Computer Music Conference: 57‐61. San Francisco: International Computer Music Association.
Dannenberg, R./ Sanchez, M./ Joseph, A./ Capell, P./ Joseph, R./ Saul, R. (1990). A Computer‐Based Multi‐Media Tutor for Beginning Piano Students. Interface ‐ Journal of New Music Research 19(2‐3): 155‐173.
Eigenfeldt, A. (2007). Real‐time Composition or Computer Improvisation? A composer’s search for intelligent tools in interactive computer music. Proceedings of the Electronic Music Studies 2007. www.ems‐network.org/IMG/pdf_EigenfeldtEMS07.pdf.
Lewis, G. (2000). Too Many Notes: Computers, Complexity and Culture in "Voyager". Leonardo Music Journal: 33‐39. Mathews, M. (1969). The Technology of Computer Music. MIT Press.
Mathews, M. V. (1980). The Sequential Drum. Computer Music Journal: 45‐59.
참고자료
Mazzoni, D./ Dannenberg, R. (2002, Summer). A Fast Data Structure for Disk‐Based Audio Recording. Computer Music Journal 26(2): 62‐76.
Rowe, R. (1992). Interactive Music Systems: Machine Listening and Composing. Cambridge, MA: MIT Press.
Solis, J./ Chida, K./ Suefugi, K./ Taniguchi, K./ Hashimoto, S. M./ Takanishi, A. (2006) The Waseda Flutist Robot WF‐4RII in Comparison with a Professional Flutist. Computer Music Journal 40(4): 12‐24.
Vercoe, B. (1985). The Synthetic Performer in the Context of Live Performance. Proceedings of the 1984 Interntional Computer Music Conference: 199‐200. International Computer Music Association.
Wessel, D./ Lavoie, P./ Boynton, L./ Orlarey, Y. (1987). MIDI‐LISP: A LISP‐Based Programming Environment for MIDI on the Macintosh. Audio Engineering Society Conference: 5th International Conference: Music and Digital Technology. AES.
Winkler, T. (1998). Composing Interactive Music: Techniques and Ideas Using Max. Cambridge, MA: MIT Press.
Xia, G./ Kawai, M./ Matsuki, K./ Fu, M./ Cosentino, S./ Trovato, G./ . . . Takanishi, A. (2016). Expressive Humanoid Robot for Automatic Accompaniment. SMC 2016 ‐ 13th Sound and Music Computing Conference, Proceedings: 506‐511.
Xia, G./ Wang, Y./ Dannenberg, R./ Gordon, G. (2015). Spectral Learning for Expressive Interactive Ensemble Performance. Proceedings of the 16th International Society for Music Information Retrieval Conference: 816‐822.
논문투고일: 2020년 10월26일
논문심사일: 2020년 12월08일
게재확정일: 2020년 12월17일
